
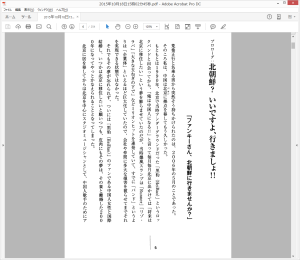
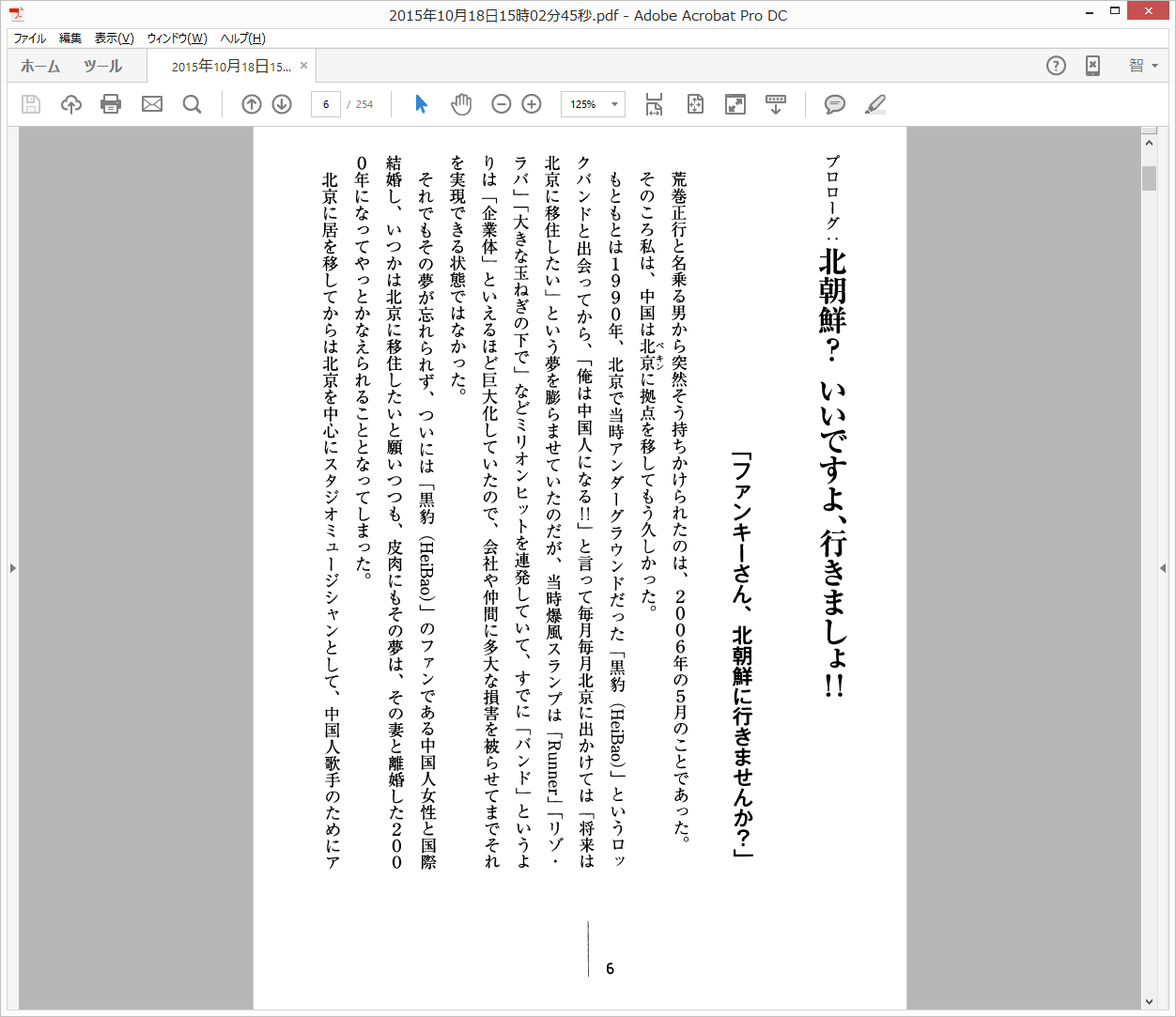
ドキュメントスキャナーで全ページのスキャンが完了して、できあがったのが↓な感じのPDF。
このまま出版できれば、どんなに楽なことかw
で、スキャナー付属のソフトにはOCRで検出したテキストをWord形式へはき出す機能もあったので、Word形式のファイルでも保存します。
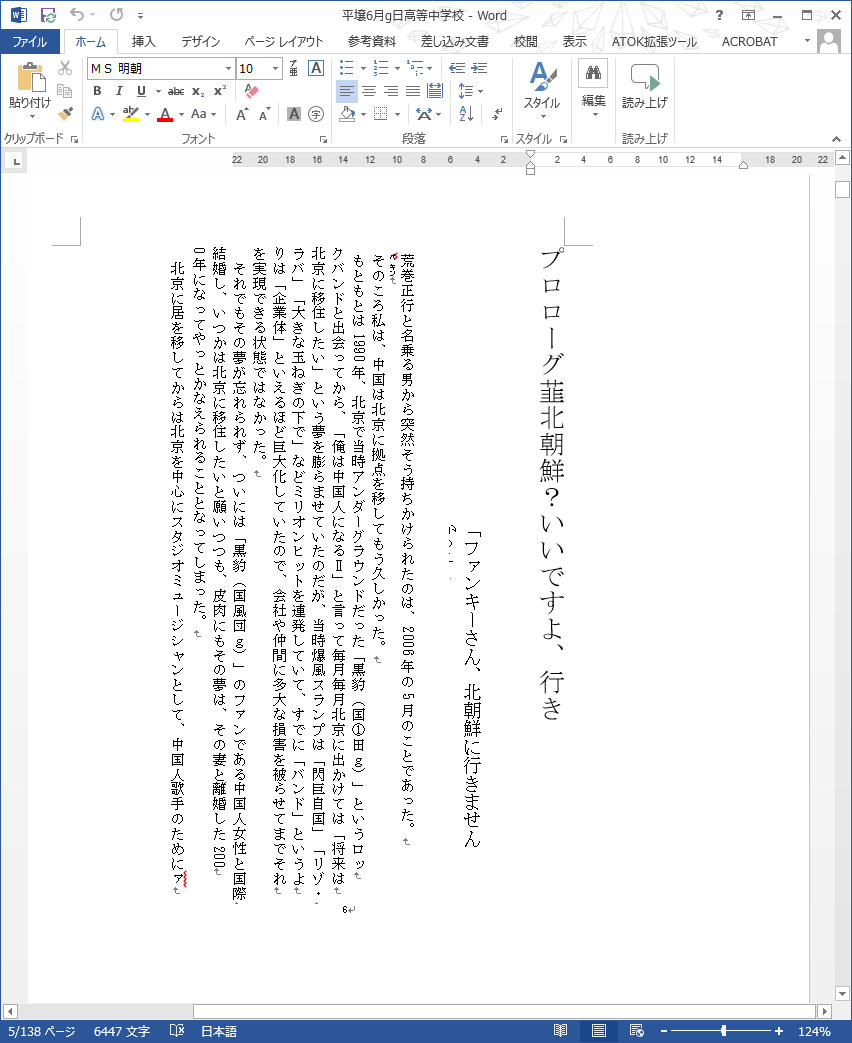
結構ちゃんと認識してますな。見た目90%以上の認識率じゃないかしら? まぁ最高画質でスキャンして、OCRは時間かけて精度の高い設定にしたので、これくらい認識してくれないと困るんですけどね。
ただ、スキャンしたレイアウトを真似てWordでもレイアウトされているので、段落ごとにブロック分けされていたり、一行ごとに改行が入っていたりとあとでKindle用データに流し込み作業をするにはめんどう。
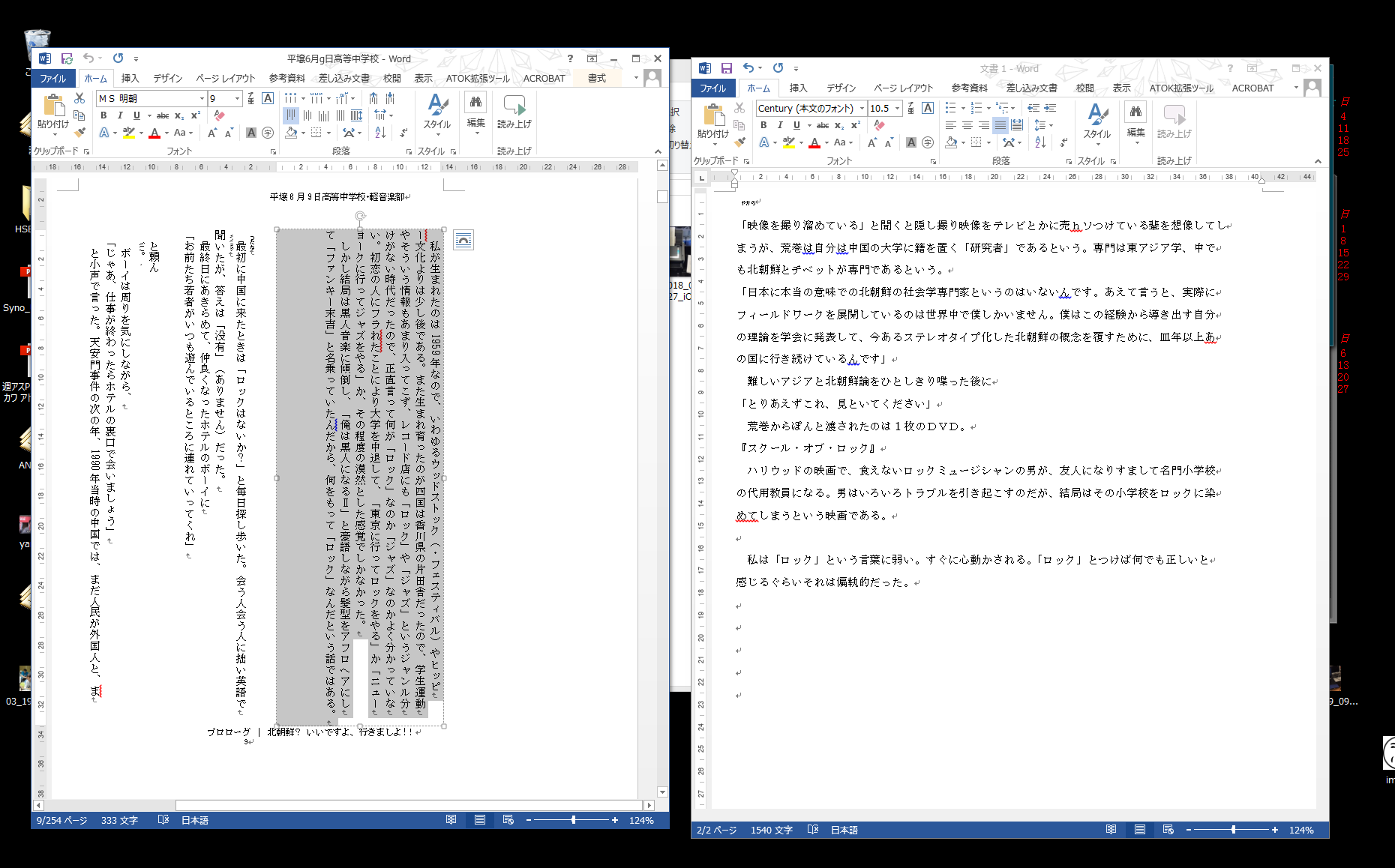
かといってこの段階でテキストエディターにコピーして作業すると、元原稿は縦なので校正するときに見比べにくい。でも改行とったりする作業は横書きのほうがやりやすいんですよね。なんせ20年間横書きで原稿書いてたから。
いちばん長く携わってる雑誌も本文は基本縦書きだけど、原稿書くときは横。ちなみに新書とかがメインの知人の作家さんは、長い原稿書くときは縦書きレイアウトじゃないとダメなので一太郎使ってるって言ってたな。
閑話休題
というわけで、いったんWordの別ファイルにコピーして、横書き状態で改行削除など整形したのち、縦書きにして印刷します。

あとは元原稿と照らし合わせて、赤字を入れていくだけ。数ページやってみたところ、修正点は“っ”と“つ”、“ァ”と“ア”の大小判別、“!!”などの記号、寝かせたアルファベットが文字化けといった程度。どこに注意して校正すればいいかだいたいわかったので、慣れてくればサクサクといけそう。
でもサクサク校正すると漏れるんですよね。校正苦手なんでw ザルです。
ちなみにマーカーでチェックしてあるところは、ルビをいれてあった文字。ルビはKindle用のデータを作るときにあらためて設定なので、ルビの入っていた文字だけあとからわかるようチェックしておきました。
で、赤字を入れた校正紙を元に、縦書きにコピーしたWordファイルの文字を直すわけです。このあたりは特別難しい作業ではなく地道な作業ですな。
全部で250ページあるので、朝の日課的作業にして、コツコツとすすめます~ >ファンキーさん

コメント